Setting Up AI Monitoring with Langfuse
People often ask how to tell a junior AI engineer from a seasoned one. My answer is simple: check their monitoring stack. If prompts, logs, and costs are invisible, the team is flying blind. In this post we unpack why monitoring should ship with version one of your AI service and how to roll out Langfuse fast.
Why Monitoring Comes Before Fine-Tuning
You won’t get to fine-tuning or fancy pipelines if you can’t see what the model does in production. Start tracking these metrics on day one:
- request cost (prompt + completion tokens)
- response latency and timeout rate
- generation quality and examples of bad answers
- user context: who made the request and in which scenario
Without this data you can’t explain a sudden spike in API spend or why users complain about a “silent” assistant. A common pitfall is leaving conversation history on, which balloons the context window and inflates costs exponentially.
Where Langfuse Helps
Langfuse is an observability platform for LLM applications. It ships both as a free cloud tier and a self-hosted option, so fitting it into company policies is easy. Key benefits:
- captures request traces, prompt chains, and nested tool calls
- stores raw model inputs and outputs for incident reviews
- counts tokens and spend per user or feature
- supports OpenAI, Hugging Face, Anthropic, and custom models
- integrates with OpenTelemetry so you can merge data with other metrics
What to Track
Treat monitoring like product analytics:
- Economics: where the budget goes and how much different features cost to run.
- Quality: which prompts draw the most complaints and how long answers take.
- Experiments: tag A/B tests of prompts or models so you can compare outcomes.
- Operational readiness: token spikes and errors are early warnings that let you fix degradation before a customer files a ticket.
Wiring Langfuse into a Python Project
Let’s walk through a basic OpenAI integration.
nodejs
// tracedOpenAi.ts
import { observeOpenAI } from '@langfuse/openai';
import { NodeSDK } from '@opentelemetry/sdk-node';
import { LangfuseSpanProcessor } from '@langfuse/otel';
import Config from '@app/config';
import { OpenAI } from 'openai/client';
const sdk = new NodeSDK({
spanProcessors: [
new LangfuseSpanProcessor({
publicKey: Config.langfusePublicKey,
secretKey: Config.langfuseSecretKey,
baseUrl: Config.langfuseHost,
}),
],
});
sdk.start();
// Wrap the OpenAI client with Langfuse tracing
export const tracedOpenAI = observeOpenAI(new OpenAI({ apiKey: Config.openAiKey }), {
// Configure trace-level attributes for all API calls
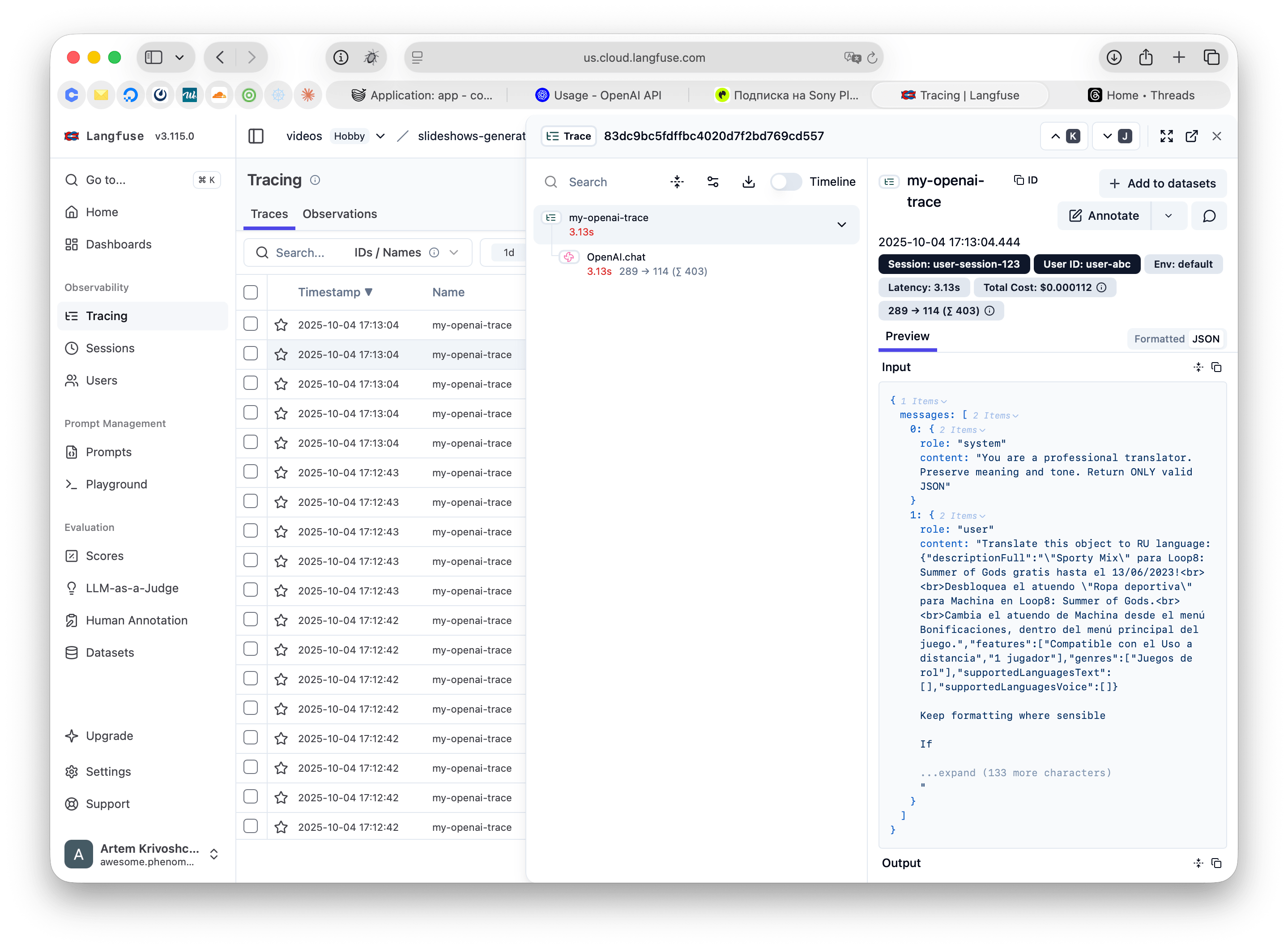
traceName: 'my-openai-trace', // Name for the trace
sessionId: 'user-session-123', // Track user session
userId: 'user-abc', // Track user identity
tags: ['openai-integration'], // Add searchable tags
});
python
# GptClient.py
from typing import Union
from langfuse.openai import OpenAI # type: ignore
from openai.types import ChatModel
from openai.types.chat import (
ChatCompletionSystemMessageParam,
ChatCompletionUserMessageParam,
)
from src.config import Config
class GptClient:
def __init__(self, api_key: str):
self.api_key = api_key
self.client = OpenAI(
api_key=Config.gpt_key(),
)
def exec_request(
self,
setup_message: str,
request_text: str,
temperature: float = 0.1,
model: Union[str, ChatModel] | None = None,
) -> str:
final_model = model if model else Config.gpt_model()
messages = [
ChatCompletionSystemMessageParam(role="system", content=setup_message),
ChatCompletionUserMessageParam(role="user", content=request_text),
]
completion = self.client.chat.completions.create(
max_tokens=40000,
model=final_model,
messages=messages,
temperature=temperature,
stream=True,
)
answer_parts = []
for chunk in completion:
part = None
if hasattr(chunk, "choices"):
delta = getattr(chunk.choices[0], "delta", None)
if delta and hasattr(delta, "content"):
part = delta.content
elif isinstance(chunk, dict) and "choices" in chunk:
part = chunk["choices"][0]["delta"].get("content", "")
if part:
answer_parts.append(part)
answer = "".join(answer_parts)
return answer
What to Inspect in Dashboards
Once the integration is live, open Langfuse and track:
- token distribution by user and scenario
- top five most expensive prompts
- share of error responses (5xx, timeouts, validation)
- example generations flagged as “bad” (add manual labels if needed)
These insights back up prioritization: you’ll know where to optimize, where to fine-tune, and where to revisit UX.
Next Steps
After a basic setup, explore advanced Langfuse features: custom metrics, automated chain retries, and collecting user feedback directly in the UI. Share your findings— the broader our toolkits, the faster we’ll build reliable AI products together.
Open for contract collaboration
I am available for contract-based collaboration. If you have an interesting project idea, schedule a call via Calendly.
Schedule a 30-min call